
Overview:
CRISP-DM Machine Learning Process
This part is about the CRISP-DM Machine Learning Process (Cross-industry standard process for data mining). Methodologies like CRISP-DM help us to organize the ML project in a way that is manageable (what needs to happen in which order).
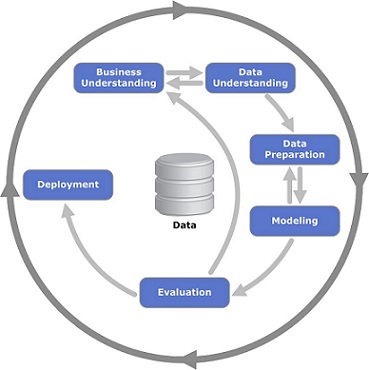
Figure 1.4.1 is from Wikipedia. You can find more information on that topic especially in the reference section there is a link to “CRISP-DM 1.0 Step-by-step data mining guide” if you need more details on that.
CRISP-DM is an iterative process with 6 steps
- Business Understanding (try to understand the problem)
- Data Understanding
- Data Preparation (often called as Feature Engineering)
- Modeling (train the model)
- Evaluation
- Deployment (using the model)
In the following more detailed descriptions of the steps there are some italic lines that are not from the course videos but from a book1.
Business Understanding
- Identify the business problem
- Detect available data sources
- Specify requirements, premises, and conditions
- Clarify risks and uncertainties
- Understand whether the problem is important
- Understand how we can solve it
- Understand how we measure the success of our project (Cost-Benefit-Analysis)
- Do we actually need ML here?
Data Understanding
- Analyze available data sources
- Collect and analyse data
- Analyze if something is missing and what is missing
- Decide if this data is good/reliable/large enough
- Decide if we need to get more data
Data Preparation (= Feature Engineering)
- Transform the data so it can be put into a ML algorithm
- Usually this means extracting different features
- Clean the data / remove all the noise
- Build the pipelines (that transform raw data into clean data)
- Convert data into tabular form (needed to put in machine learning model)
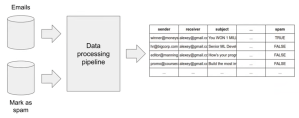
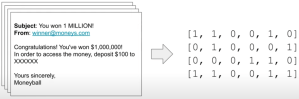
Feature Engineering is a key element of every ML project. There is a quote of Andrew Ng, Professor of the Standford University, about Feature Engineering: “Coming up with features is difficult, time-consuming, requires expert knowledge. ‘Applied Machine Learning’ is basically feature engineering.” I found this quote in a very good german book. This contains a chapter about the CRISP-DM model and Feature Engineering.2
In addition, I found on towardsdatascience.com an old but still interesting article on this subject. There, the importance of feature engineering is also highlighted.
Modeling
- Train the model (the actual ML happens here)
- Try different models
- Logistic regression, Decision tree, Neural network, others
- Select model parameters
- Try to improve model quality
- Select the best one
- Sometimes, we may go back to data preparation
- Add new features
- Fix data issues
- General aspect that I’ve learned from practice: model quality significantly depends on data quality -> keep in mind: Garbage in, Garbage out!
Evaluation
- Measure how well the model solves the business problem
- Is the model good enough?
- Have we reached the goal?
- Do our metrics improve?
- Goal: Reduce the amount of spam by 50%
- Have we reduced it? By how much?
- (Evaluate on the test group)
- Do a retrospective:
- Was the goal achievable?
- Did we solve/measure the right thing?
- After that, we may decide to:
- Go back and adjust the goal
- Roll out the model to more users/all users
- Stop working on the project
Evaluation + Deployment (Often happens together)
- Online evaluation: evaluation of live users
- It means: deploy the model, evaluate it
Deployment (=engineering practices)
- After online evaluation of some users -> deploy the model to production (all remaining users)
- Roll out the model to all users
- Proper monitoring
- Ensuring the quality and maintainability
- -> when we deploy model it has to work, it has to be reliable
- After that we care about scalability and other things
- Like in project management this includes creating the final report
Iterate!
- ML projects require many iterations!
- After deployment we come back to business understanding to check how can we improve the model or decide that it needs to be improved or not.
General note
- Start simple (e.g. with a simple model)
- Learn from feedback
- Improve (e.g. come back to business understanding and make this model a bit more complex)

Are those two books the same?
BTW. Thank you for this additional helpful notes.
LikeLike
Hello andisugandi,
thank you for your comment. If your question points to the two linked sources of that post, then yes they refer to the same book.
Peter
LikeLike