
Adjusting the learning rate
What’s the learning rate ?
Let’s use an analogy. Imagine that learning rate is how fast you can read and you read one book per quarter. That means you can read 4 books per year. Somebody else can read 1 book per day, so he can read many books per year. But maybe he is just skimming through them and looking at the table of content or just flipping the book through and looking at the concepts there. But when he tries to apply this readings, he cannot remember a lot.
Somebody else reads just one book per year and she reads very slow and takes some notes very carefully. This way she makes sure that she remember everything then she learns really well.
The many-books reader is similar to a high learning rate. This could be too fast. The expected performance on validation data could be poor, because the model tends to overfit.
The 4-books reader is similar to medium learning rate. This could be ok. The expected performance on validation data could be good.
And the last reader is similar to low learning rate. This is very effective but very very slow. The expected performance on validation data could be poor, because the model tends to underfit.
Trying different values
Therefor we use the code from the previous section and put it to a function. The middle part of this function could be separated to a function called “create_architecture”, but we’ll keep it simple here.
def make_model(learning_rate=0.01):
base_model = Xception(
weights='imagenet',
include_top=False,
input_shape=(150, 150, 3)
)
base_model.trainable = False
#########################################
inputs = keras.Input(shape=(150, 150, 3))
base = base_model(inputs, training=False)
vectors = keras.layers.GlobalAveragePooling2D()(base)
outputs = keras.layers.Dense(10)(vectors)
model = keras.Model(inputs, outputs)
#########################################
optimizer = keras.optimizers.Adam(learning_rate=learning_rate)
loss = keras.losses.CategoricalCrossentropy(from_logits=True)
model.compile(
optimizer=optimizer,
loss=loss,
metrics=['accuracy']
)
return model
We want to iterate over different values of learning rate.
scores = {}
for lr in [0.0001, 0.001, 0.01, 0.1]:
print(lr)
model = make_model(learning_rate=lr)
history = model.fit(train_ds, epochs=10, validation_data=val_ds)
scores[lr] = history.history
print()
print()
# Output:
# 0.0001
# Epoch 1/10
# 96/96 [==============================] - 135s 1s/step - loss: 1.9380 - accuracy: 0.3523 - val_loss: 1.6440 - val_accuracy: 0.4399
# Epoch 2/10
# 96/96 [==============================] - 127s 1s/step - loss: 1.4122 - accuracy: 0.5306 - val_loss: 1.2856 - val_accuracy: 0.5660
# Epoch 3/10
# 96/96 [==============================] - 135s 1s/step - loss: 1.1628 - accuracy: 0.6232 - val_loss: 1.0895 - val_accuracy: 0.6745
# Epoch 4/10
# 96/96 [==============================] - 138s 1s/step - loss: 1.0163 - accuracy: 0.6718 - val_loss: 0.9715 - val_accuracy: 0.6979
# Epoch 5/10
# 96/96 [==============================] - 137s 1s/step - loss: 0.9194 - accuracy: 0.7040 - val_loss: 0.8962 - val_accuracy: 0.7214
# Epoch 6/10
# 96/96 [==============================] - 132s 1s/step - loss: 0.8488 - accuracy: 0.7223 - val_loss: 0.8406 - val_accuracy: 0.7449
# Epoch 7/10
# 96/96 [==============================] - 136s 1s/step - loss: 0.7952 - accuracy: 0.7451 - val_loss: 0.8006 - val_accuracy: 0.7654
# Epoch 8/10
# 96/96 [==============================] - 136s 1s/step - loss: 0.7520 - accuracy: 0.7555 - val_loss: 0.7656 - val_accuracy: 0.7683
# Epoch 9/10
# 96/96 [==============================] - 130s 1s/step - loss: 0.7163 - accuracy: 0.7679 - val_loss: 0.7460 - val_accuracy: 0.7801
# Epoch 10/10
# 96/96 [==============================] - 129s 1s/step - loss: 0.6853 - accuracy: 0.7683 - val_loss: 0.7183 - val_accuracy: 0.7801
# 0.001
# Epoch 1/10
# ...
# Epoch 10/10
# 96/96 [==============================] - 125s 1s/step - loss: 1.1078 - accuracy: 0.9417 - val_loss: 10.6175 - val_accuracy: 0.7801
del scores[0.1]
del scores[0.0001]
for lr, hist in scores.items():
plt.plot(hist['accuracy'], label=('train=%s' % lr))
plt.plot(hist['val_accuracy'], label=('val=%s' % lr))
plt.xticks(np.arange(10))
plt.legend()
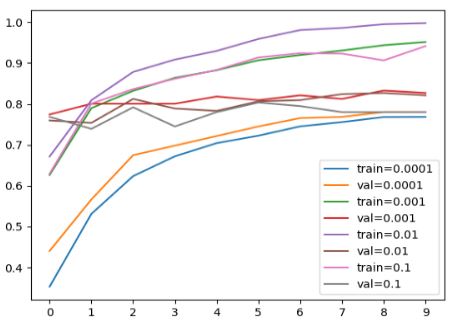
learning_rate = 0.001
What we did so far we tried different models with different learning rates and the we choose this one that is best on validation data. Another interesting thing is comparing the difference between train and validation data between different learning rates – the smaller the better.
